Pipeline de Datos Ecommerce con Airflow, dbt y Snowflake
Este proyecto desarrolla un pipeline de procesamiento de datos para un ecommerce, utilizando Airflow, dbt y Snowflake. El enfoque está en la generación, ingesta y transformación de datos sintéticos, implementando las capas bronze y silver para estructurar y preparar la información para análisis posteriores. Aunque se sigue la filosofía de la arquitectura medallion, en esta etapa solo se han implementado las primeras capas, dejando gold y marts como próximos pasos.
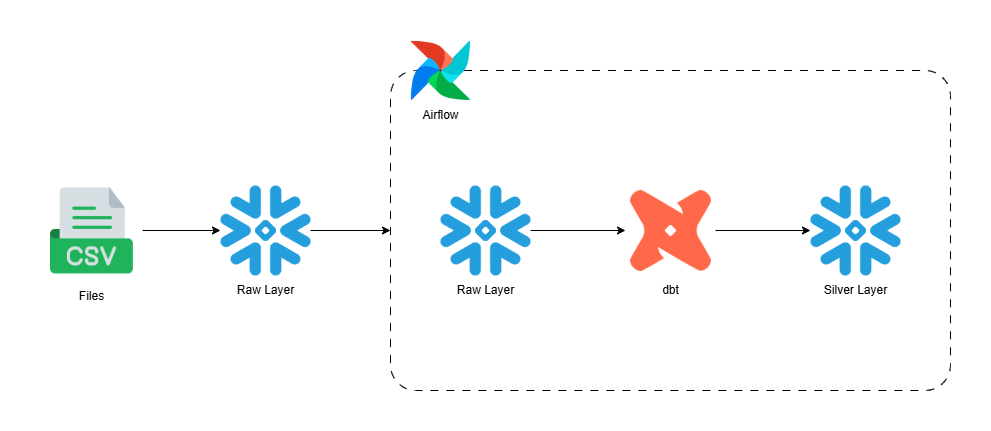
Flujo de Datos
-
Generación de Datos Sintéticos: Se han creado múltiples archivos CSV que simulan datos reales de un ecommerce (clientes, productos, ventas, inventario, campañas de marketing, eventos web y reseñas de clientes). Estos archivos se encuentran en la carpeta
include/data_generation/data/. -
Carga a Snowflake (Bronze Layer): Utilizando un DAG de Airflow, los archivos CSV se cargan en tablas de la capa bronze en Snowflake (
bronze_ecommerce). Cada archivo corresponde a una tabla, permitiendo la ingesta inicial y centralizada de los datos sin transformaciones. -
Transformación y Modelado (Silver Layer): Los datos de la capa bronze se leen desde Snowflake y se procesan para generar vistas en la capa silver. Aquí se aplican transformaciones, limpieza y enriquecimiento de los datos, facilitando su uso analítico. Los modelos y transformaciones de la silver layer están definidos en la carpeta
include/dbt/models/silver/.
Herramientas Utilizadas
- Airflow 3: Orquestación de los flujos de carga y transformación de datos mediante DAGs.
- dbt: Modelado de datos, generación de vistas y macros para facilitar transformaciones reutilizables y parametrizadas.
- Snowflake: Almacenamiento y procesamiento de los datos en las distintas capas (bronze y silver).
Macros en dbt
Se han implementado macros en dbt para estandarizar y automatizar transformaciones comunes, como la generación de claves, manejo de fechas y limpieza de datos. Estas macros permiten mantener el código DRY y facilitan la escalabilidad del proyecto.
Decisiones Relevantes
- Se optó por la generación de datos sintéticos para simular un entorno realista y flexible de pruebas.
- La carga inicial se realiza en la capa bronze para preservar la integridad y granularidad de los datos generados.
- Las transformaciones en la capa silver permiten preparar los datos para análisis, manteniendo trazabilidad y calidad.
- El uso de Airflow y dbt permite una orquestación y modelado modular, escalable y reproducible.
Próximos Pasos
- Implementar modelos y vistas en la capa gold y marts para análisis avanzados y reportes de negocio.
- Integrar validaciones y monitoreo de calidad de datos.
- Documentar y expandir el uso de macros personalizadas en dbt.